Building A Natural Language Enabled Pandas Dataframe Agent With LangChain & OpenAI
In this article, we walk thru the steps to build your own Natural Language enabled Pandas DataFrame Agent using the LangChain library and an OpenAI account. We also test the limits of what the Large Language Model can(‘t) do and briefly explore the latest developments in other Business Intelligence / Data & Analytics platforms. Finally, but most importantly — we discuss why BI Analysts don’t have to worry about losing our jobs (at least not just yet :P)

Introduction
I know most professional business analysts out there are hard-core SQL fanatics but I have a soft spot for Python’s Pandas (Fun Fact : did you know that Panda is actually an abbreviation for Panel Data! )
In my previous Medium article, I covered how you can build your own Python Script For Natural Language Q&A Using LlamaIndex
This time round, rather than working with unstructured text, we are going to see if Large Language Models can help us literally talk to our (data) tables.

Chapter Headings
- >Introduction
- >Sample Data Sets
- >Setting Up LangChain and an OpenAI Account
- >Creating An Agent And Making Data Queries
- >What Else Can LangChain Do ?
- >>Multi Dataset Queries
- >>Beyond Pandas
- >>Vector Stores & Embedding Databases
- >Zooming Out — How Is Generative AI Being Adopted By Business Intelligence & Analytics Platform Providers
- >Not So Fast…Let’s Take A Closer Look At The Results
- >Conclusion — So Are The Bots Going To Take Over?
All the code used below are available in this GitHub repository if you’d like to follow along as well
Sample Data Sets
We’ll be using the excellent public data sources available from Our World In Data website (Seriously — if you can afford it — please donate to their cause, it is ridiculous that they’ve made all this data available for free)
Let’s use the dataset on CO2 and Greenhouse Gas Emissions which “includes data on CO2 emissions (annual, per capita, cumulative and consumption-based), other greenhouse gases, energy mix, and other relevant metrics”
import pandas as pd
import matplotlib.pyplot as plt #We'll need this later...
df1 = pd.read_csv("owid-co2-data.csv")Typically, in a full blown Pandas Tutorial (that you can lookup elsewhere) we would do some exploratory data analysis via df.describe() and df.info() plus some general data wrangling to remove N/A-s and other weird stuff
However for the purposes of this article, we’ll skip this step and jump straight into how we can start “talking to our tables”. (Spoiler alert —as we will see later — this turned out to be a bad idea so word of advice — don’t skip the fundamentals )
Setting Up LangChain and an OpenAI Account
There are a few python libraries out there that do the trick but we’ll use LangChain partly because it is general purpose enough that once we get used to creating agents for Pandas DataFrames , the same approach can be applied to almost anything else (as we’ll see later on)
LangChain is a framework designed to develop applications powered by large language models (LLM-s), with a focus on being data-aware and agent-like by creating indexing structures so that LLMs can more efficiently retrieve information, remember previous interactions and generate customized (memory & context aware) responses to user queries
First up, we’ve got to install LangChain…
pip install langchainand next we’’ll import a couple of key components to get set-up.
from langchain.agents import create_pandas_dataframe_agent
from langchain.chat_models import ChatOpenAI
from langchain.agents.agent_types import AgentType
from langchain.llms import OpenAIFor this article we’ll be using OpenAI’s LLM but it should be noted that LangChain has integrations with a wide range of Large Language Models such as HuggingFace, Cohere ,Anthorpic and lots more….
It’s not free but it’s relatively inexpensive to use (especially if you are just starting to learn this) and all you need to do is to sign up for an OpenAI Account and get an OpenAI API Key to use with LangChain.
Once you’ve gotten your API Key, we’ll put it into an environment variable that LangChain will refer to
import os
os.environ["OPENAI_API_KEY"] = "PASTE YOUR SECRET KEY HERE"Important Side Note : If you decide to replicate this code-along with your own (private) data — although OpenAI has since issued a statement that say that they “do not use data submitted to and generated by our API to train OpenAI models or improve OpenAI’s service offering”, you may want to carefully consider if there is anything sensitive about the datasets you are exposing to the OpenAI algorithm.
Creating An Agent And Making Data Queries
With the setup out of the way, next we can create a Pandas Dataframe “Agent” to talk to the CO2 & Greenhouse Gas Emissions data set (i.e df1)
agent = create_pandas_dataframe_agent(
ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
df1,
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
)…and now we’re ready to ask the the agent whatever we can think of….
To get warmed up, we can begin with some very basic questions like
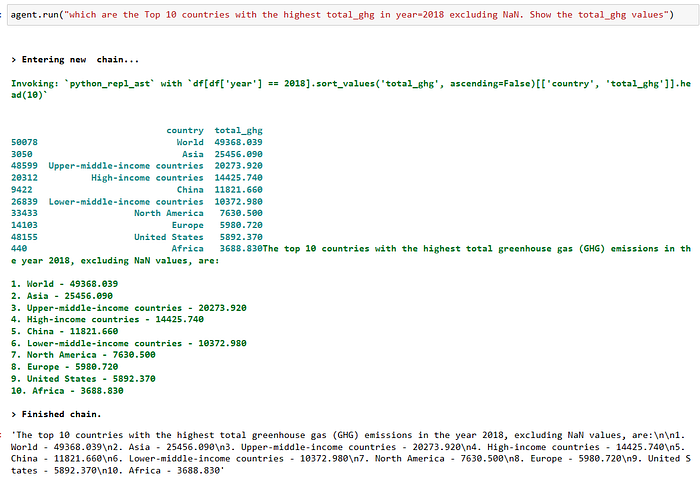
Okay that was alright I guess but what about a couple of more challenging questions…?
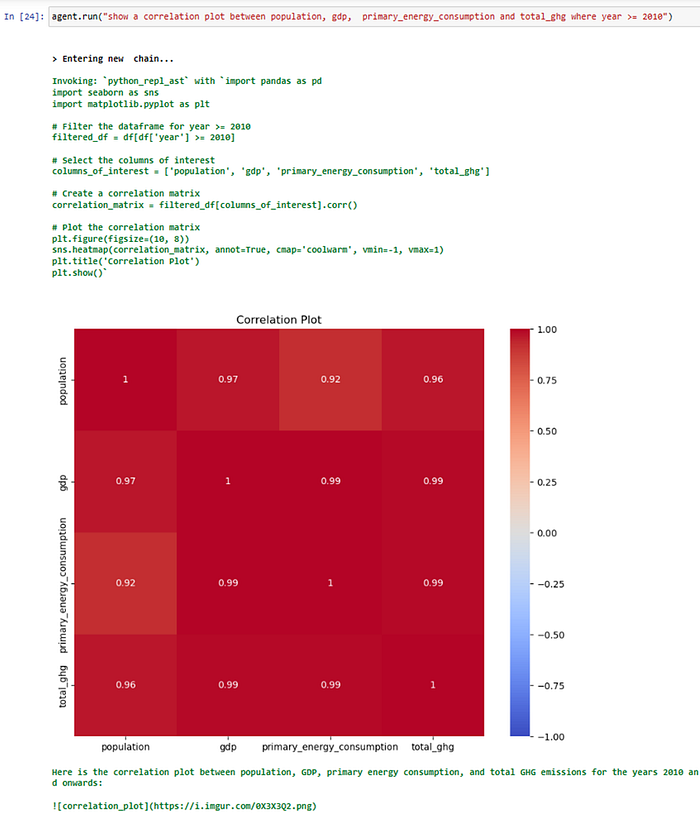
Hmmm….what else can the LangChain agent do ?

What Else Can LangChain Do ?
Multi Dataset Queries
Let’s grab a second dataset on Energy from the same Our World In Data website which contains “data on energy consumption (primary energy, per capita, and growth rates), energy mix, electricity mix and other relevant metrics”
df2 = pd.read_csv("owid-energy-data.csv")Next — let’s upgrade our agent to accept both dataframes and then we can get down to asking it some tougher questions….
Multi_DF_agent = create_pandas_dataframe_agent(
ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
[df1,df2],
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,
)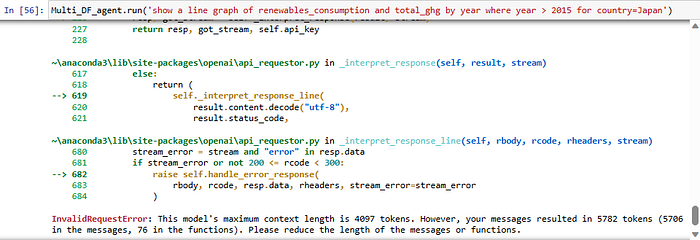
As you can see in the screenshot — the agent choked as we hit the token limit with the query

Unfortunately OpenAI hasn’t yet released GPT4 for general use (which unlike GPT3.5 which maxes out at 4096 tokens, GPT4 can handle 8,000 tokens and if you are willing to fork out $$$, it can go up to 32,000 (!) tokens)
So let’s see if we can simplify the datasets and rephrase the prompt to get it to work. We’ll shrink the size of the datasets to focus only on the columns that we care about and then reset the agent.
df1 = df1[['country', 'year','iso_code','total_ghg']]
df2 = df2[['country', 'year','iso_code','renewables_consumption']]
#Let's reinstantiate the agent and feed it the smaller df1 and df2
Multi_DF_agent = create_pandas_dataframe_agent(
ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613"),
[df1,df2],
verbose=True,
agent_type=AgentType.OPENAI_FUNCTIONS,)Here goes…
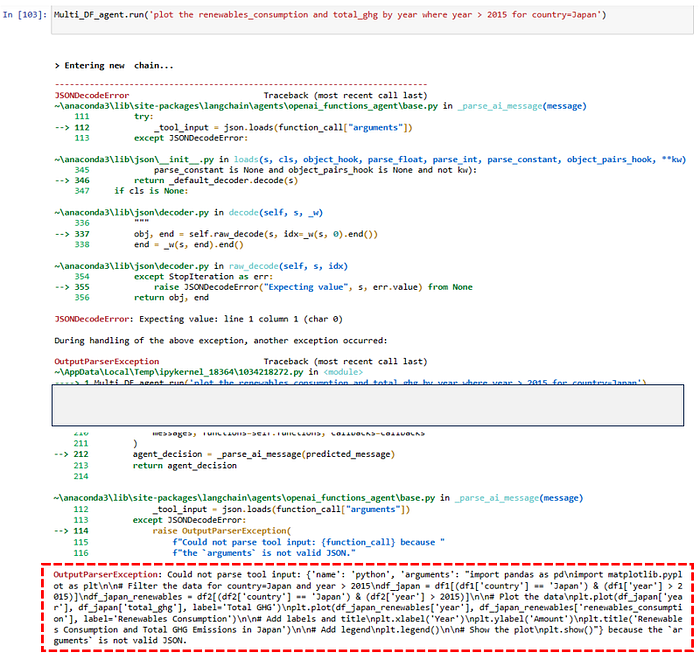
Even though it spat out an error , there was a really useful bit of text right at the end where it still suggested some code even though it somehow wasn’t able to run it.
If we take that suggested code and cut/paste it into a new cell….(The algorithm even helpfully writes the comments and notes along with the code)
import pandas as pd
import matplotlib.pyplot as plt
# Filter the data for country=Japan and year > 2015
df_japan = df1[(df1['country'] == 'Japan') & (df1['year'] > 2015)]
df_japan_renewables = df2[(df2['country'] == 'Japan') & (df2['year'] > 2015)]
# Plot the data
plt.plot(df_japan['year'], df_japan['total_ghg'], label='Total GHG')
plt.plot(df_japan_renewables['year'], df_japan_renewables['renewables_consumption'], label='Renewables Consumption')
# Add labels and title\nplt.xlabel('Year')
plt.ylabel('Amount')
plt.title('Renewables Consumption and Total GHG Emissions in Japan')
# Add legend
plt.legend()
# Show the plot
plt.show()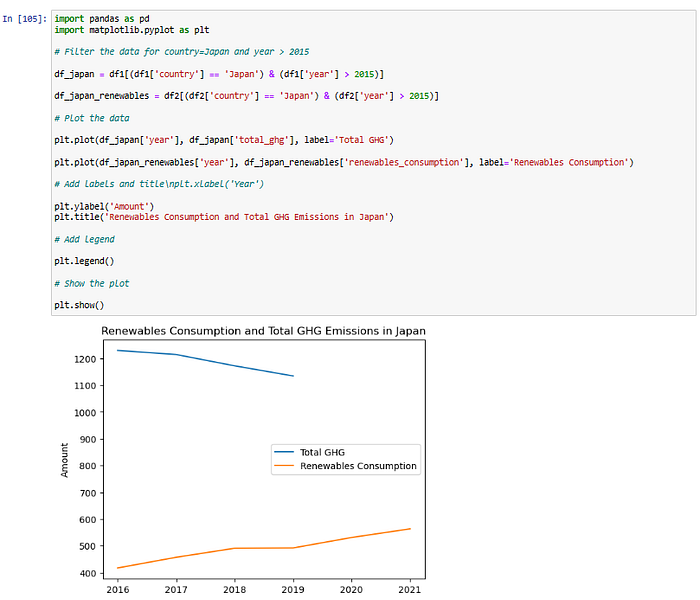
It did take a bit more effort than expected but at the end,even though it was not fully automatic, the agent managed to suggest some useful code that we still had to help it cut and paste into a new cell…
Beyond Pandas
It would be beyond the scope of the article to cover all the different use cases but suffice to say that the example we just walked thru is similar for CSV-s and also SQL Databases where LangChain also has agents for these applications too.
Vector Stores & Embedding Databases
For the slightly more advanced readers who want to explore the topic further, there are also ways to combine LangChain with other vector store / embedding database tools such as PineCone , Chroma or LlamaIndex.
Vector embeddings in AI/ML is a way of representing data as points in n-dimensional space so that similar data points cluster together. Another way to describe it is that it is a way to abstract data into a higher order view where the position of those points in space encode some meaningful info. Vector stores in turn are databases that store , index and then retrieve all these vector embeddings.
Essentially all of this make your agents smarter by providing structures for them to better remember past queries and understand context
Zooming Out — How Is Generative AI Being Adopted By Business Intelligence & Analytics Platform Providers
As demonstrated in the LangChain example, LLM-s are a form of “translation service” to convert natural language questions into “data speak” leveraging the LLM’s pre-trained knowledge of how certain phrases or words are related in order to convert a question “in plain english” into a complicated query that a machine can understand
While the above example is a bit involved and needs a bit of effort to learn some programming , many of the major business intelligence platform providers are already jumping onto the Generative LLM based AI bandwagon in a BIG way.
Microsoft
PowerBI recently announced in May 2023 the release of its AI powered CoPilot feature. (Note — What’s even crazier is CoPilot is itself only just one of the other long list of interesting and new features within Microsoft Fabric which has the ambitious goal to provide an end-to-end data and analytics platform that integrates all of Microsoft’s data and analytics tools)
===============================================================
Side Note: Even Excel which is the go-to tool for almost all business professionals has gotten an AI facelift in the last few months where it has a stripped down version of the same sort of natural language interface.
===============================================================
Salesforce
Not to be outdone, Saleforce’s Tableau also announced a slew of Generative AI powered features for their platform in the form of Tableau Pulse and Tableau GPT (Which confusingly — despite of the name Tableau GPT is actually built on top of Salesforce’s Einstein GPT which uses a variety of LLMs, including some developed by its partner OpenAI but also other proprietary models)
Not So Fast…Let’s Take A Closer Look At The Results
Ok, even I have to admit, all of the above is pretty impressive and it would seem like these developments pose an existential question for Data Analysts everywhere : What role can we still play in a “soon to arrive” world where everyone can easily pull info to make their own reports and dashboards (I.e Like how almost everyone has baseline Excel skills)?
However if you look past the wow factor , you may notice a few things that seem a bit ‘off’.
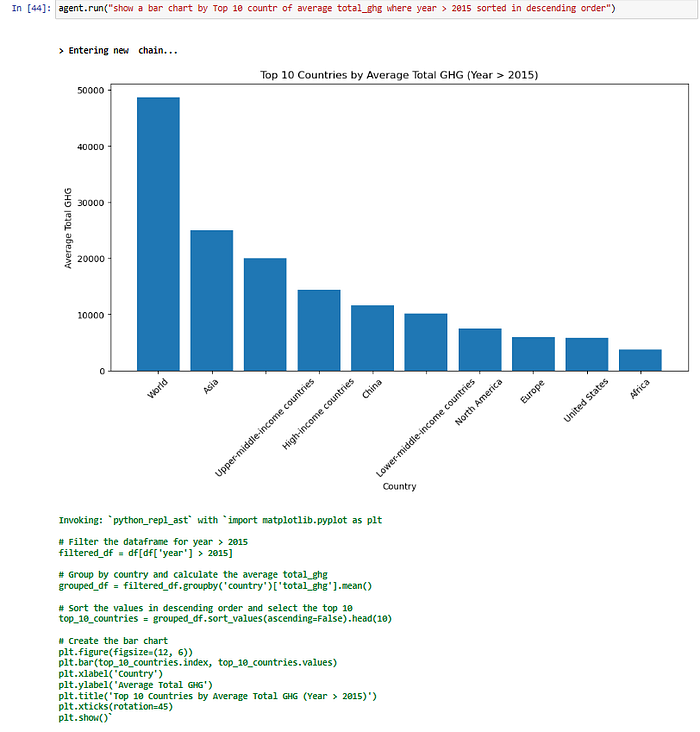
For example revisiting the query where I asked the agent to plot a bar graph of the average annual Total GHG by country , the country field seems to be a blend of Regions : World , Asia , Income groups like : Upper Middle Income and High Income countries and actual Countries like China.
Therefore I had to dig into the source data itself and looking at the table natively , can quickly see that only “true” countries have an ISO code.

Therefore a better prompt would need to include “…where iso_code is not blank…” like so

Also in the second question where (with some manual help) the agent managed to plot the Total GHG vs Renewables Consumption, you may have noticed gaps in the data where there wasn’t any GHG data for Japan in 2020 and 2021 which to be fair is not an algorithmic problem but one of underlying data completeness.
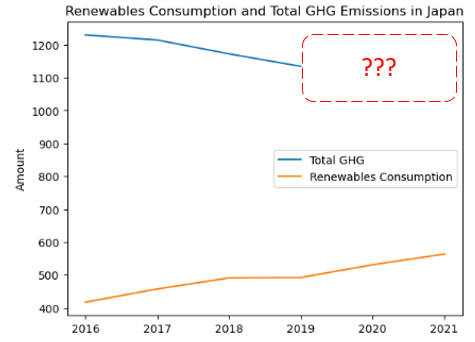
If we modify the prompt slightly to include “replace blank values with an exponentially weighted moving average of window = 2 years”
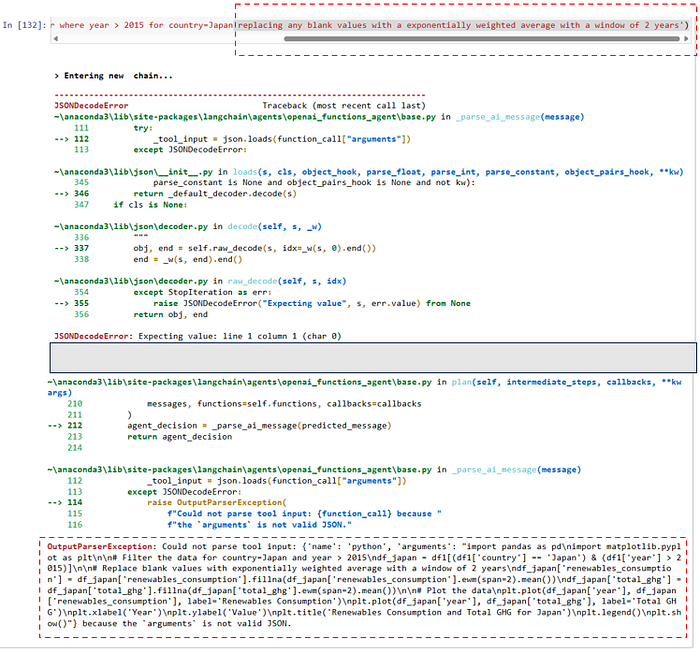
Applying the same trick as before where even though the algorithm choked, we pick up the text at the bottom and stick it into a new cell

Although…you may notice the chart is terribly mis-leading as we never prompted the agent to highlight where the data was “synthetic” and to ensure any assumptions (i.e. use of EWMA of Span=2) is prominently displayed on the chart. (Never mind the fact that it was also a completely arbitrary choice to use EWMA of period 2 vs a simple rolling mean of period x)
Conclusion — So Are The Bots Going To Take Over?

So to recap — in this article we went thru the steps to build your own Natural Language enabled Pandas DataFrame Agent using the LangChain library.
We also pushed the limits of what these LLM agents are able to do and took a detour to latest developments in other Business Intelligence platforms and how they are applying the same sort of Generative AI tech
At the end of all this , you might be asking the question if the bots are going to take over. My response is NO (Not Yet At Least :P)
This sort of LLM tech has an amazing potential to unlock better insights from our data and democratize the use of analytics for anyone who can ask great questions.
I’m pretty hopeful of what the future will bring. If done right, this should liberate time for data analysts who would otherwise be burdened with “.. could you get me this or that figure but exclude this category and can I have this in a horizontal bar chart but make sure the font is in helvetica…” to instead have higher quality conversations around what business problem users are trying to solve and coaching them to help themselves to develop better data driven narratives.
It’s also a clarion call for Business / Data Analysts to future proof ourselves where our worth as analysts will need to go beyond just skill-sets in ETL or data visualization.
One obvious path could be the technical route of investing more focus on complex forward looking /predictive type questions…(ie Data Analysts levelling up to be Data Scientists)
I do think that is part of the answer but what is far more interesting is if we can lean into the aspect of business partnering and asking better CONTEXT specific data questions that help our stakeholders make better decisions or take actions that add enterprise value.
What LLM Agents can’t do (for now) is provide human intuition and the ability to know how to listen, ask why , frame their work (eg. what is the problem we are trying to solve, who are we solving it for, why is it important) and contextualise data stories so end users can take action/make decisions that matter.
An often-used abbreviation of Data & Analytics is DnA but really it should be Decisions & Actions that matter.

What do YOU think is coming next for the Data Analytics discipline ? Let’s continue the chat in the comments section.
